Program Verification: Proving Your Implementation Actually Does What You Think
You’ve shipped the lock-free queue. Tests pass on your laptop, staging looks clean, benchmarks hold up. Then at 2:47 AM, production starts returning corrupted data. The test suite said it worked. It didn’t work.
The problem isn’t missing tests — it’s that tests verify some executions. Verification proves behavior across all possible executions. That’s not a philosophical distinction; it’s the difference between a bug showing up in staging versus silently eating user data for six months.
The Verification Stack Nobody Talks About
Production systems need layered verification. Each layer catches a different class of bug that the others miss entirely.
Layer 1: The Compiler’s Verifier
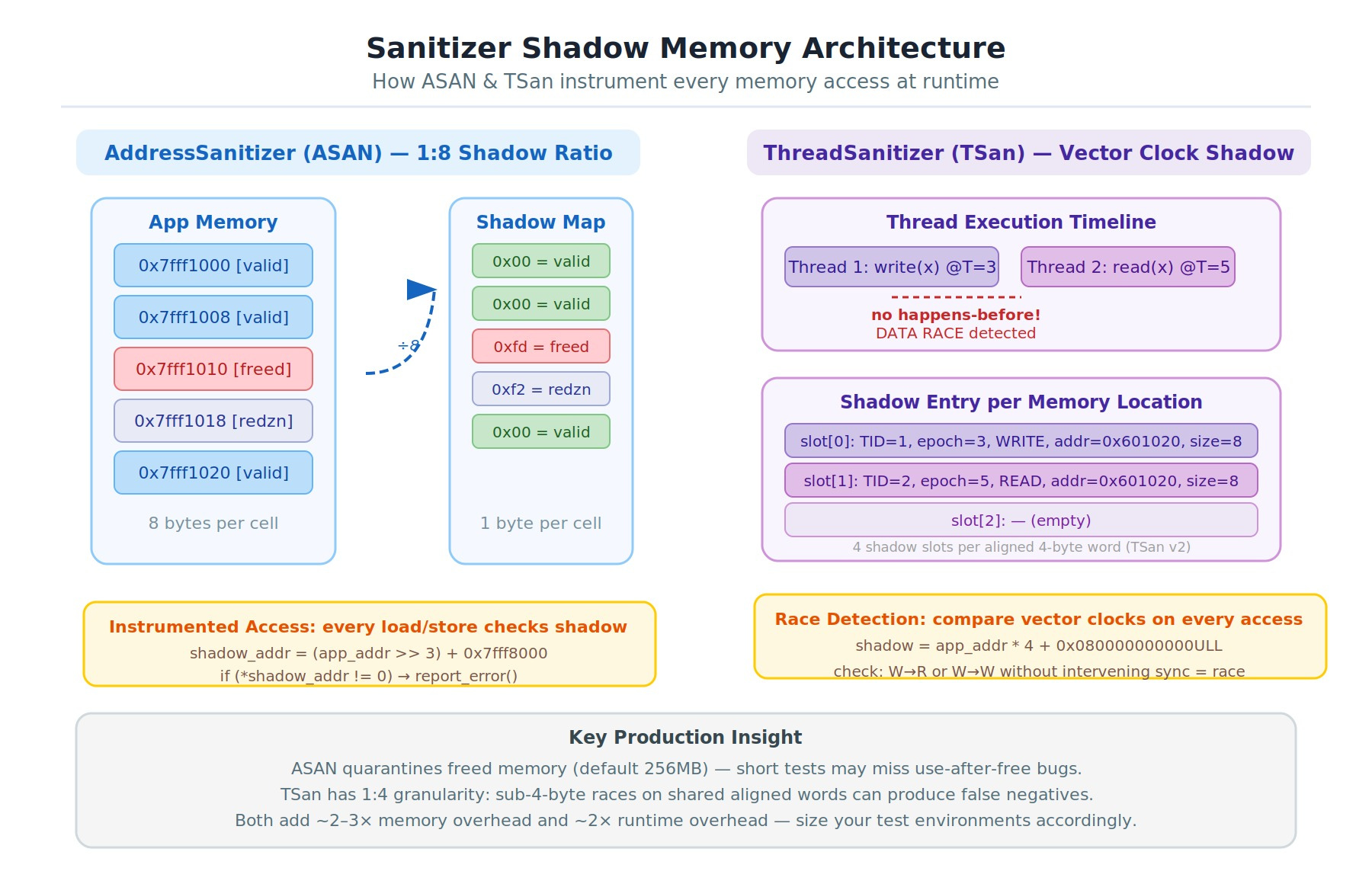
GCC and Clang’s sanitizer suite isn’t “debugging tools” — it’s a lightweight runtime verifier that instruments every memory access, every arithmetic operation, and every thread synchronization point.
-fsanitize=addressrewrites your binary so every load and store checks a shadow memory region that tracks allocation state. The shadow map uses a 1:8 ratio: 8 bytes of your application memory maps to 1 shadow byte, encoding whether those bytes are valid, freed, poisoned, or unaddressable.What this catches that valgrind misses: stack use-after-return (UAR), where a pointer to a local variable escapes the function. The kernel’s own KASAN (Kernel Address Sanitizer) uses the same technique to catch bugs in subsystems that have been “stable” for years — it found a stack-use-after-free in the ext4 driver that had survived code review for three kernel releases.
Layer 2: Concurrency Verification with Shadow State
ThreadSanitizer maintains a happens-before graph as a shadow for every memory location — specifically, a vector clock. Each byte of application memory has a corresponding shadow storing the last four accesses (two reads, two writes) with their timestamps. When a new access comes in, TSan checks whether any conflicting access happens-before the new one. If not: data race.
The implementation detail that matters: TSan uses a 1:4 shadow ratio with a 4-byte aligned granularity. This means it cannot distinguish races on sub-4-byte objects that share an aligned word. You can have a legitimate race that TSan silently misses, or a false positive on lock-free code that uses intentional benign races. Knowing this saves hours when TSan flags your hazard pointer implementation.