Post-Mortem Analysis: Core Dump Generation and Inspection in High-Availability Systems
Your service just segfaulted at 3 AM. The process is gone, monitoring shows nothing useful, and you need to know what happened. This is where core dumps become critical—but only if they’re actually being generated.
Why Core Dumps Fail in Production
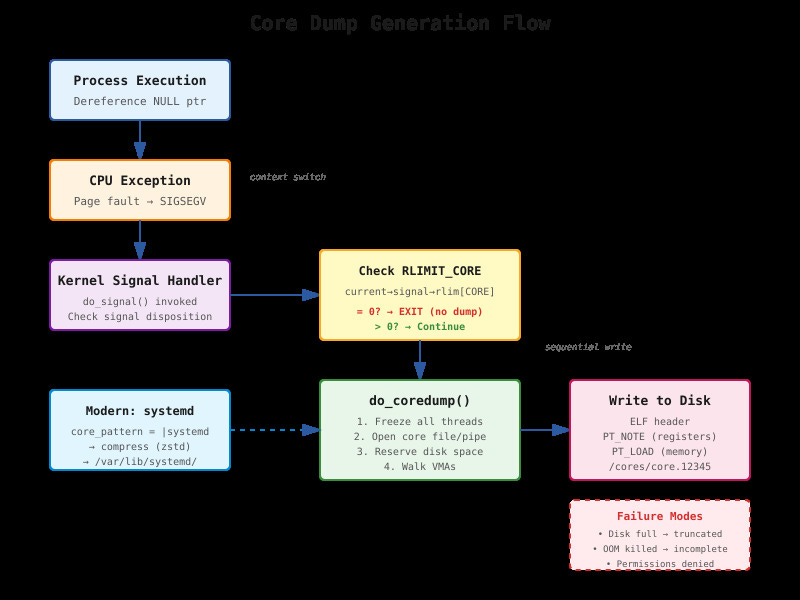
Most production systems have
RLIMIT_COREset to zero. Check yours right now:ulimit -cprobably returns 0. This means when your process crashes, the kernel skips dump generation entirely. Even if you set it to unlimited, a 16GB process creates a 16GB+ core file. If you’re on a filesystem that’s 90% full, the write fails mid-dump and you get nothing.The second killer is container environments. Your Kubernetes pod writes the core to
/cores, but that path isn’t mounted to persistent storage. The pod restarts, ephemeral storage gets wiped, and your evidence disappears. I’ve spent entire incident responses debugging phantom crashes because no one configured a PersistentVolume for cores.