Memory Allocators: malloc vs. tcmalloc vs. jemalloc — What Really Happens
Systems Programming Deep Dive — Issue 1
Most services run on the allocator that shipped with glibc and never think about it. That’s fine until your allocation-heavy microservice starts spending 40% of wall time in
_int_mallocand your on-call rotation gets interesting.
The Problem Nobody Tells You About
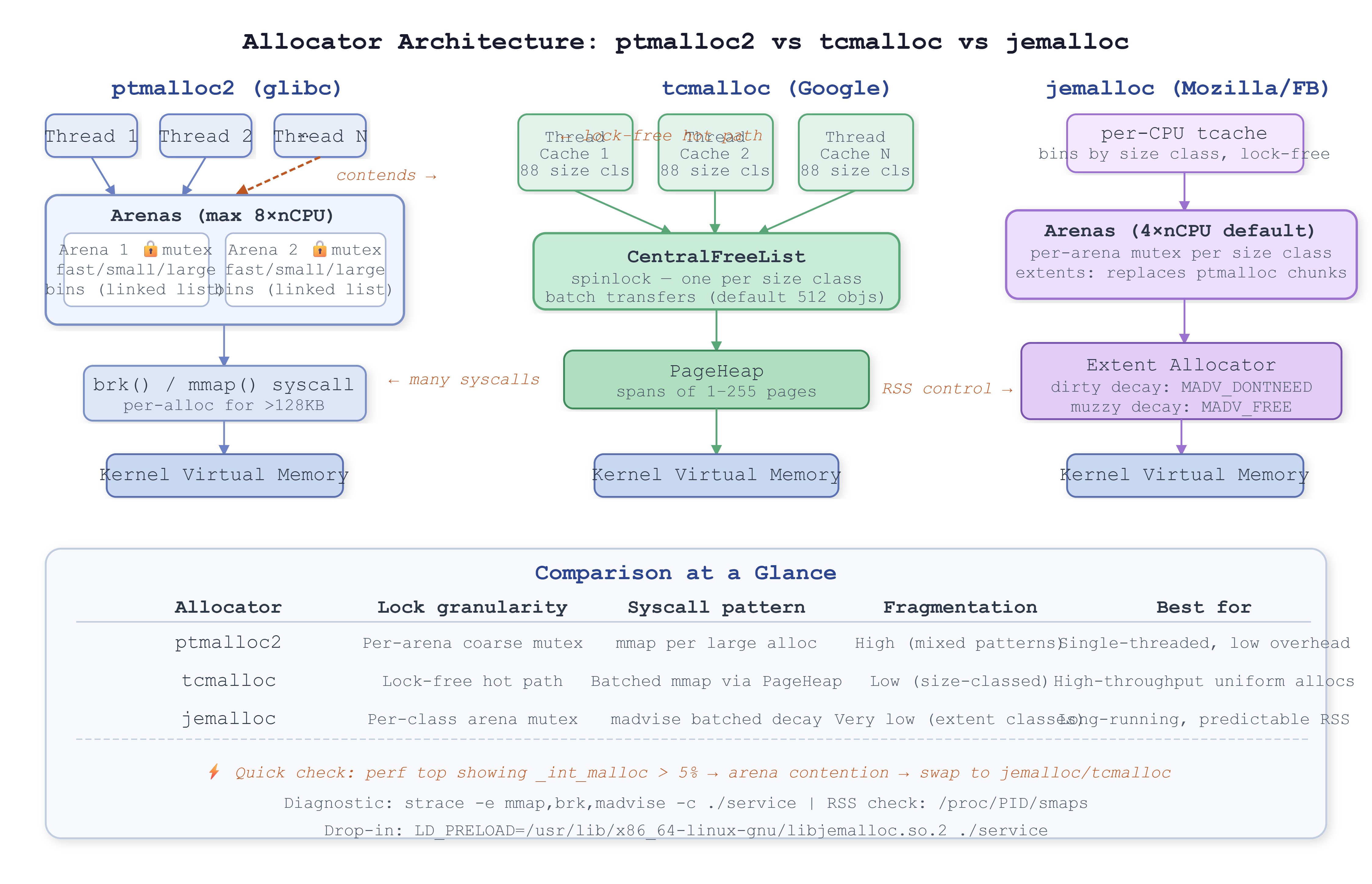
glibc’s allocator — ptmalloc2, unchanged since 2006 — was designed for single-threaded workloads and patched for threading later. The seams show. Each arena is a coarse-grained lock over a linked list of chunks. Under moderate thread contention,
perf topstarts looking like this:
37.12% libc.so [.] _int_malloc
14.88% libc.so [.] _int_free
8.43% kernel [k] futex_wait_queue_me
That
futex_waitline is threads sleeping on arena locks. You’re paying context switch cost on every allocation path, and the faster your threads allocate, the worse it gets.