Linux OOM Killer: How the Kernel Decides Which Process Dies
Systems Programming Deep Dive | Memory Management Series
Every production engineer eventually stares at a dead process and a dmesg line ending with:
Killed process 14392 (postgres) total-vm:8388608kB, anon-rss:4194304kB
Understanding exactly why Postgres died instead of the Python analytics job next to it means understanding oom_badness() — the kernel function that produces the death warrant.
Part I — How It Works
The Overcommit Contract
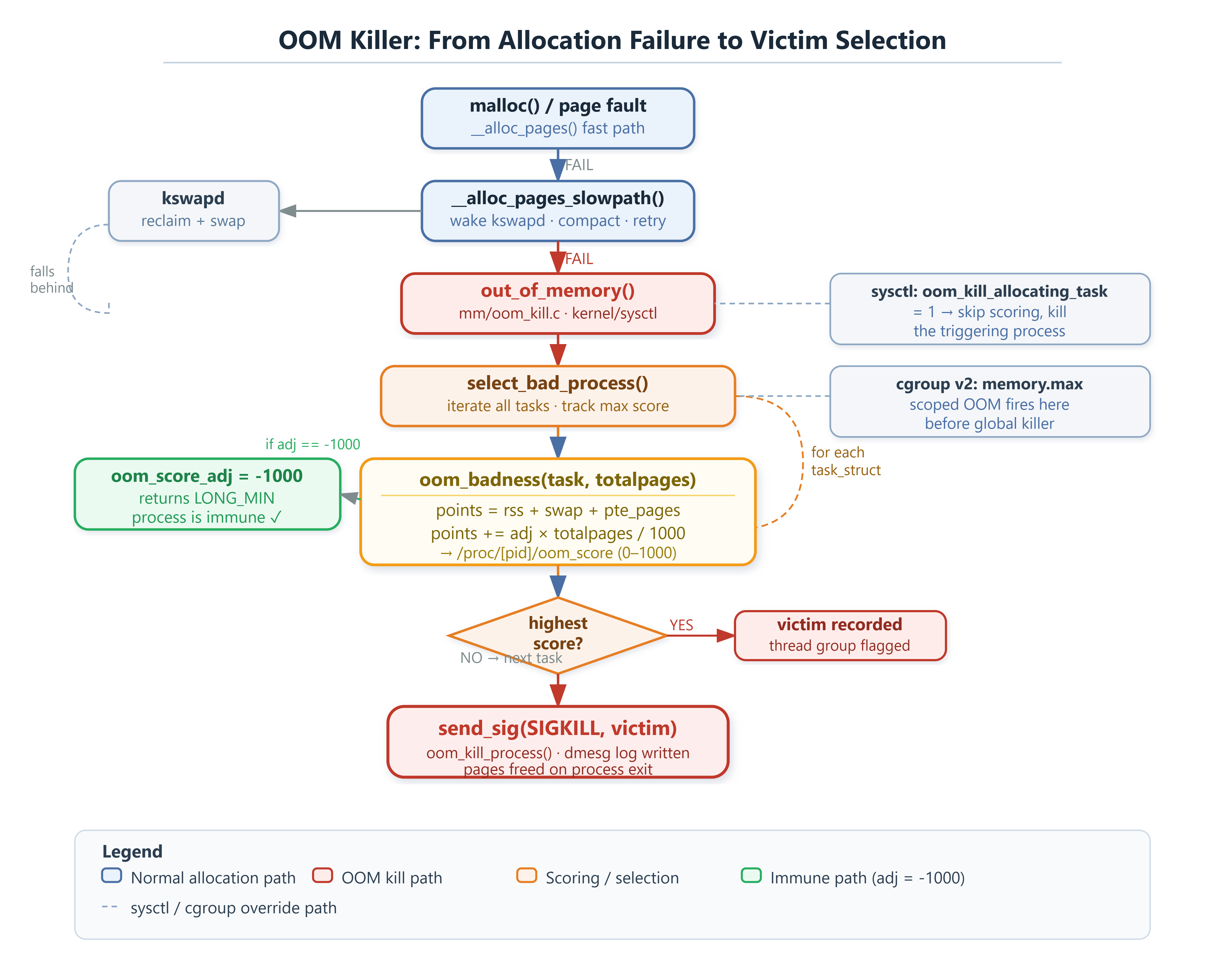
Linux lies to your processes. When you call
malloc(1GB)on a machine with 256MB free, the kernel says yes, maps virtual address space, and hands back a pointer. No physical memory is committed. Pages only get faulted in on first write — demand paging. This isvm.overcommit_memory = 0(heuristic mode), where the kernel estimates likelihood of use and accepts most requests.The consequence: your system can carry 40GB committed virtual memory on 16GB RAM plus 8GB swap.
/proc/meminfotracks this viaCommitLimit(the ceiling) andCommitted_AS(what’s actually promised). When real demand exceeds physical capacity,kswapdactivates — reclaims clean page cache, writes dirty anonymous pages to swap. Whenkswapdfalls behind and direct reclaim inside__alloc_pages_slowpath()fails, the allocating CPU thread is about to block indefinitely. That’s whenout_of_memory()gets called.
The Scoring Algorithm
oom_badness()inmm/oom_kill.creduces each candidate process to a single integer. The formula:
points = rss_pages + swap_pages + page_table_pages
points += (oom_score_adj / 1000.0) × total_ram_pages
RSS here counts anonymous pages (heap, stack, anonymous mmap) plus file-backed mapped pages. Swap usage is added directly — a process that’s been heavily paged out still carries its full working set in the score. Page table overhead is included too; processes with fragmented mappings pay extra.
The
/proc/[pid]/oom_score_adjknob ranges from -1000 to +1000. At -1000,oom_badness()returnsLONG_MIN— the process is unconditionally immune. At +1000, the adjustment adds the equivalent of all system RAM to the raw score, making selection near-certain. The/proc/[pid]/oom_scorevalue you read is this normalized to 0–1000 relative to total RAM.
select_bad_process()iterates every task on the system, callsoom_badness()for each, and returns the highest scorer. Thread groups are evaluated as a unit — if one thread scores highest, the entire process dies.