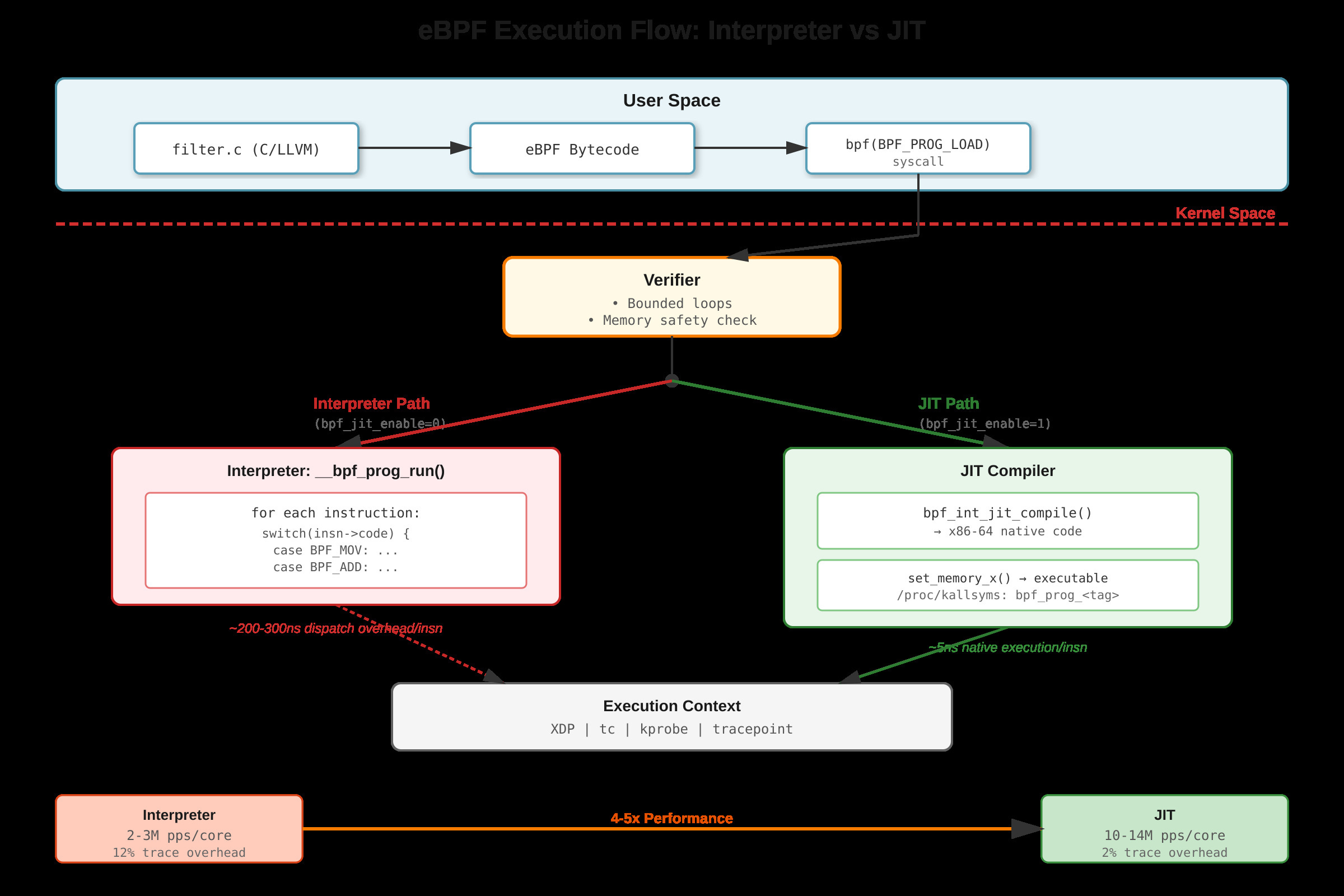
JIT Compilation for eBPF: Optimizing Bytecode Execution in the Kernel
When your XDP packet filter is burning 40% CPU and you’re dropping packets at 10Gbps, the culprit is often simpler than you think: eBPF interpreter mode is still enabled. I’ve debugged this exact scenario at 3 AM when someone forgot to check
bpf_jit_enableafter a kernel upgrade. The performance difference isn’t subtle—it’s 4-5x.
The Interpreter Bottleneck
eBPF programs execute as bytecode in the kernel, running in contexts like XDP (network packet processing), kprobes (kernel tracing), or tc (traffic control). Without JIT, the kernel interpreter
__bpf_prog_run()walks each eBPF instruction sequentially. Every instruction hits an indirect branch in a giant switch statement—roughly 200-300 nanoseconds of dispatch overhead per instruction. For a simple XDP program processing 10 million packets per second, that dispatch overhead alone consumes entire CPU cores.The interpreter thrashes instruction cache because both bytecode and dispatch logic compete for the same cache lines. Branch predictors fail on the switch statement since the next instruction type is unpredictable. TLB pressure increases because the interpreter needs separate page mappings for bytecode storage and execution logic.