
DNS Resolution Delay: The Silent Killer That Blocks Your Threads
Your service is humming along at 2,000 requests per second with beautiful 50ms p99 latency. Then your internal DNS resolver starts responding in 300 milliseconds instead of 3 milliseconds. Within seconds, your thread pool is 95% utilized, request latency jumps to 500ms, and your error rate climbs to 20%. What just happened?
This is one of the sneakiest failure modes in distributed systems because it masquerades as a performance problem when it’s really a resource exhaustion problem. Let me show you exactly how this works and why even experienced engineers miss it during incidents.
The Blocking Problem Everyone Forgets
Here’s the thing about DNS lookups that catches people off guard. When your service needs to connect to another service, it has to resolve the hostname to an IP address. In most programming languages, this happens through a synchronous system call like getaddrinfo(). That means the thread making the request just sits there, doing nothing, waiting for the DNS response.
Normally this takes 2-5 milliseconds and nobody notices. You have a thread pool of 200 threads, each request takes maybe 50ms total, and you’re processing thousands of requests per second without breaking a sweat. The occasional DNS lookup is just noise in the overall request time.
But when DNS gets slow, everything changes. Imagine your DNS resolver is now taking 300ms to respond. Every thread that needs to establish a new connection is now blocked for 300ms just waiting for DNS. During that time, incoming requests pile up in the queue. More threads pick up queued requests, and they also need new connections, so they also get stuck on DNS. Before you know it, your entire thread pool is blocked waiting for DNS responses, and your service is effectively dead even though your CPU is at 15% and you have plenty of memory.
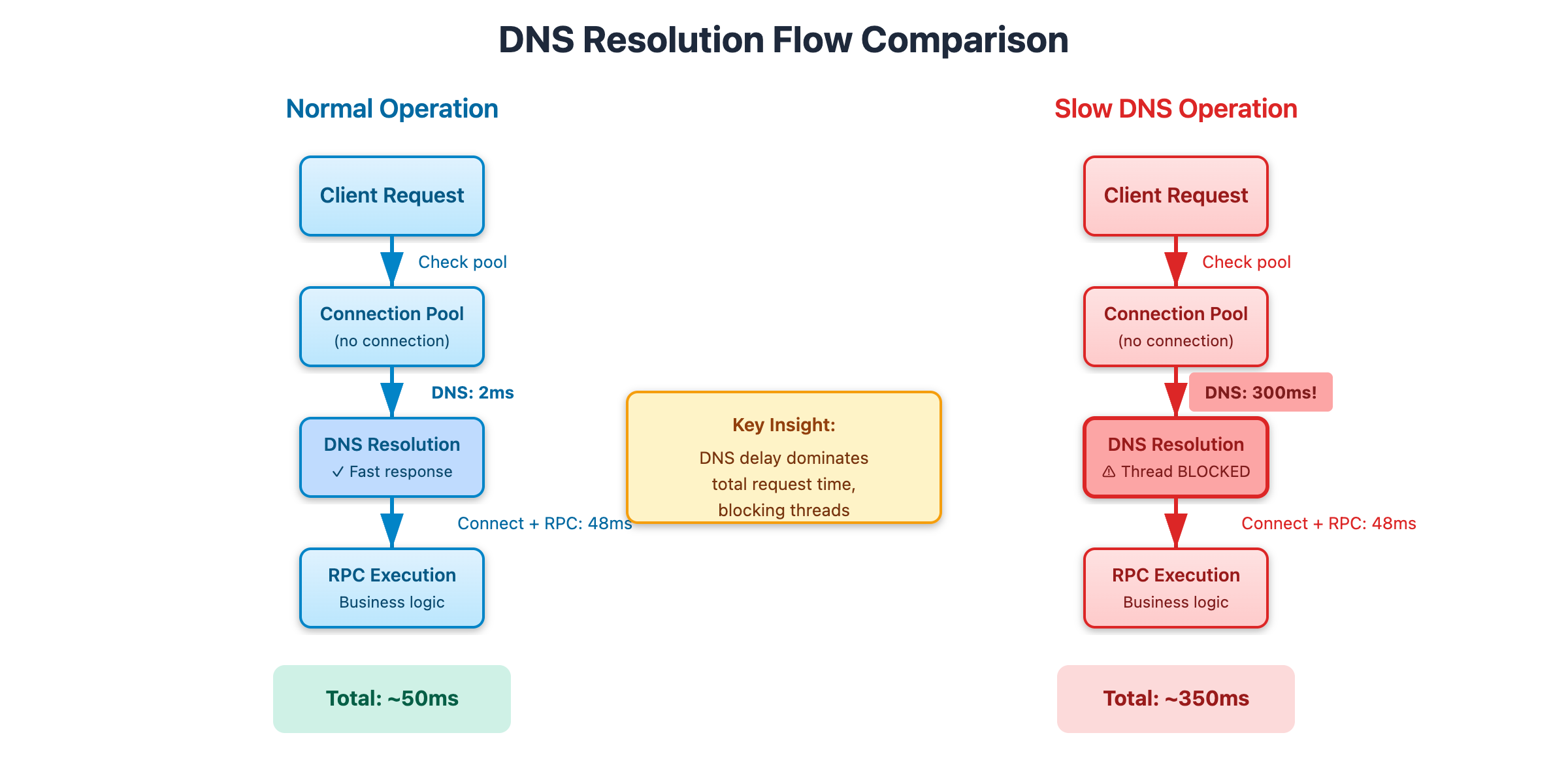
[Diagram 1: Request Flow Comparison - Shows normal 50ms request with 2ms DNS vs degraded 350ms request with 300ms DNS, highlighting thread blocking]
The Stuff That Actually Trips You Up
Let me tell you about the JVM’s DNS caching behavior because it has caused more production outages than I can count. By default, the JVM caches successful DNS lookups forever. Not for 30 seconds, not for 5 minutes, literally forever until you restart your process. This was a security decision to prevent DNS rebinding attacks, but it means when you deploy a new version of a service and the IP changes, old instances can’t see the new instances until they restart. You need to explicitly set networkaddress.cache.ttl in your security properties or system properties, and most people don’t know this exists.
Go has its own DNS quirks. It has two different DNS resolvers: a pure Go implementation and one that uses cgo to call the system’s resolver. The pure Go resolver doesn’t respect your /etc/hosts file, which is why things work on your Mac but fail in your container. Which resolver it uses depends on your OS and build flags, and you can end up with different behavior in different environments.
In Kubernetes, there’s a phenomenon I call the “deployment DNS storm.” You have 1,000 pods all using CoreDNS for service discovery. Each pod has connections to 10 different services. When you do a rolling deployment and pods restart, they all need to re-establish connections, which means 10,000 DNS queries in a short window. If your CoreDNS isn’t scaled properly (and the defaults aren’t good enough past ~3,000 pods), it gets overwhelmed, response times spike, and everything cascades.
Here’s another one that’s bitten me: negative DNS caching. When a DNS lookup fails, resolvers cache that failure for 5-10 minutes by default. So if your service is briefly unavailable during a deployment, clients trying to reach it get a failed DNS lookup, cache that failure, and can’t reach your service for the next 10 minutes even after it comes back up. You need to tune negative cache TTLs separately from positive ones.
How This Spreads Through Your System
The cascading failure pattern is brutal. Let’s say you have Service A calling Service B calling Service C. Service C’s DNS resolver gets slow. Now Service B’s threads are blocked waiting for DNS to resolve Service C’s address. This means Service B is slow to respond to Service A. Service A’s threads are now blocked waiting for Service B, even though Service A’s DNS resolver is fine. Incoming requests to Service A pile up, and pretty soon your whole system is grinding to a halt because of a DNS issue in one downstream service.
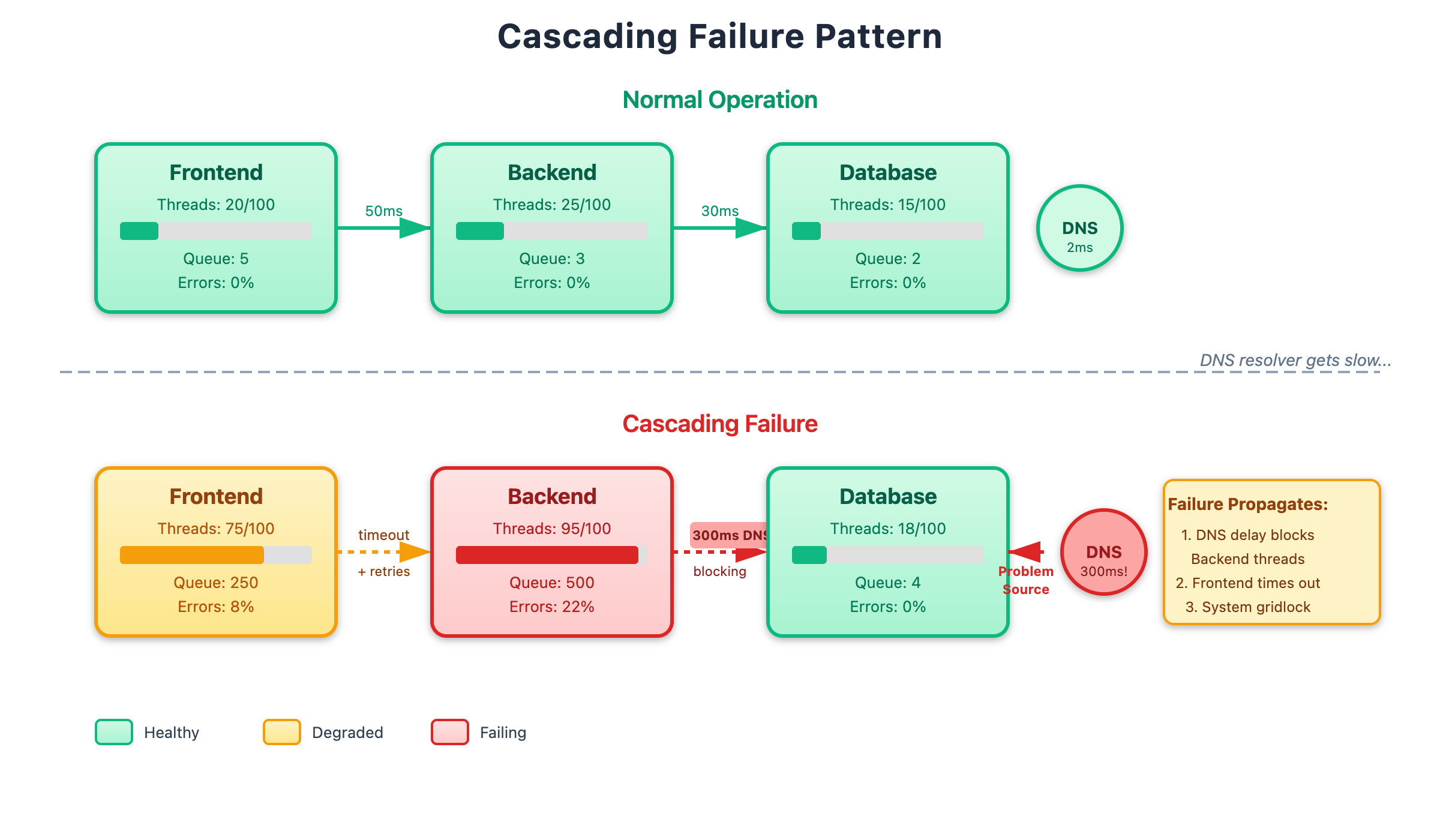
[Diagram 2: Cascading Failure - Shows three services in a chain, with DNS delay in the deepest service causing thread pool exhaustion to propagate upstream]
The retry behavior makes it worse. When Service A times out waiting for Service B, it often retries. So now Service B is getting the original request plus retries, all while its threads are blocked on DNS. This is the “retry storm” that turns a small problem into a complete outage.
Real Production War Stories
At AWS, I saw a team hit this when they scaled their service from 100 instances to 1,000 instances during a traffic spike. Each instance was making around 50 DNS queries per minute for various backend services. That went from 5,000 queries/min to 50,000 queries/min instantly. Their internal DNS resolvers couldn’t handle it, response times went from 2ms to 400ms, and the entire service locked up despite having capacity to handle the traffic.
Netflix wrote about this with their Zuul API gateway. The gateway was creating a new connection for every backend call, which meant constant DNS lookups. They solved it with aggressive connection pooling and a custom DNS cache layer that refreshes entries in the background before they expire, so the cache is always warm. This is the “stale-while-revalidate” pattern applied to DNS.
The Kubernetes CoreDNS bottleneck is so common there’s now a standard solution called NodeLocal DNSCache. It runs a caching DNS server on every node, so pods hit a local cache instead of CoreDNS for every lookup. But it’s not enabled by default, so teams hit the scaling wall and spend days figuring out what’s wrong.
What You Should Do About This
First, measure DNS resolution time separately from request latency. Most monitoring tools don’t break this out, so you don’t notice when DNS is slow. Add instrumentation that tracks how long getaddrinfo() or your language’s equivalent takes. If p99 DNS time goes above 50ms, investigate immediately.
Set aggressive timeouts on DNS lookups. Most systems default to 5 seconds or even 30 seconds, which is absurd. Set it to 500ms maximum. Yes, you’ll get more DNS failures, but better to fail fast and have threads available than block all your threads for 30 seconds.
Implement your own DNS caching layer with TTLs you control. Don’t trust language defaults. Cache resolved addresses for 30-60 seconds, and when entries are about to expire, refresh them in the background while continuing to serve the cached value. This eliminates DNS latency from the request path entirely.
For Kubernetes, definitely enable NodeLocal DNSCache and reduce the NDOTS setting from the default of 5 to 2. This dramatically reduces DNS query volume. Also scale CoreDNS based on your pod count, not just the default 2 replicas.
Run multiple DNS resolvers and use client-side load balancing. Never have a single DNS server as a point of failure. In AWS, use multiple Route53 resolver endpoints in different AZs.
Finally, add circuit breakers around operations that do DNS lookups. If DNS starts failing or slowing down, trip the circuit, fail fast, and serve stale cached data instead of blocking all your threads.
Try It Yourself
I’ve built a demo that shows this failure mode in action. You’ll see a microservice system handling steady traffic, then we’ll inject DNS delay and watch the cascade happen in real time. The dashboard shows you request latency, DNS resolution time, thread pool utilization, and error rate, so you can see exactly how everything connects.
Run through it once in a controlled environment and you’ll recognize the pattern instantly when you see it in production at 3 AM. That’s worth the 10 minutes it takes to set up.
working demo code
github repo link : https://github.com/sysdr/howtech/tree/main/dns_resolution