Developing a Custom DSQ Manager for sched_ext
Linux 6.12 shipped sched_ext — not another scheduler policy sitting alongside CFS, but a framework that lets you replace the entire scheduling algorithm with a BPF program, live, without rebooting. The primitive that makes this work is the Dispatch Queue (DSQ). Get DSQ management wrong and you either leave CPUs starved while work piles up in your custom queues, trigger the watchdog that forcibly evicts your scheduler back to CFS, or silently starve low-priority tasks until your batch jobs stop making progress entirely.
What a DSQ Is at the Kernel Level
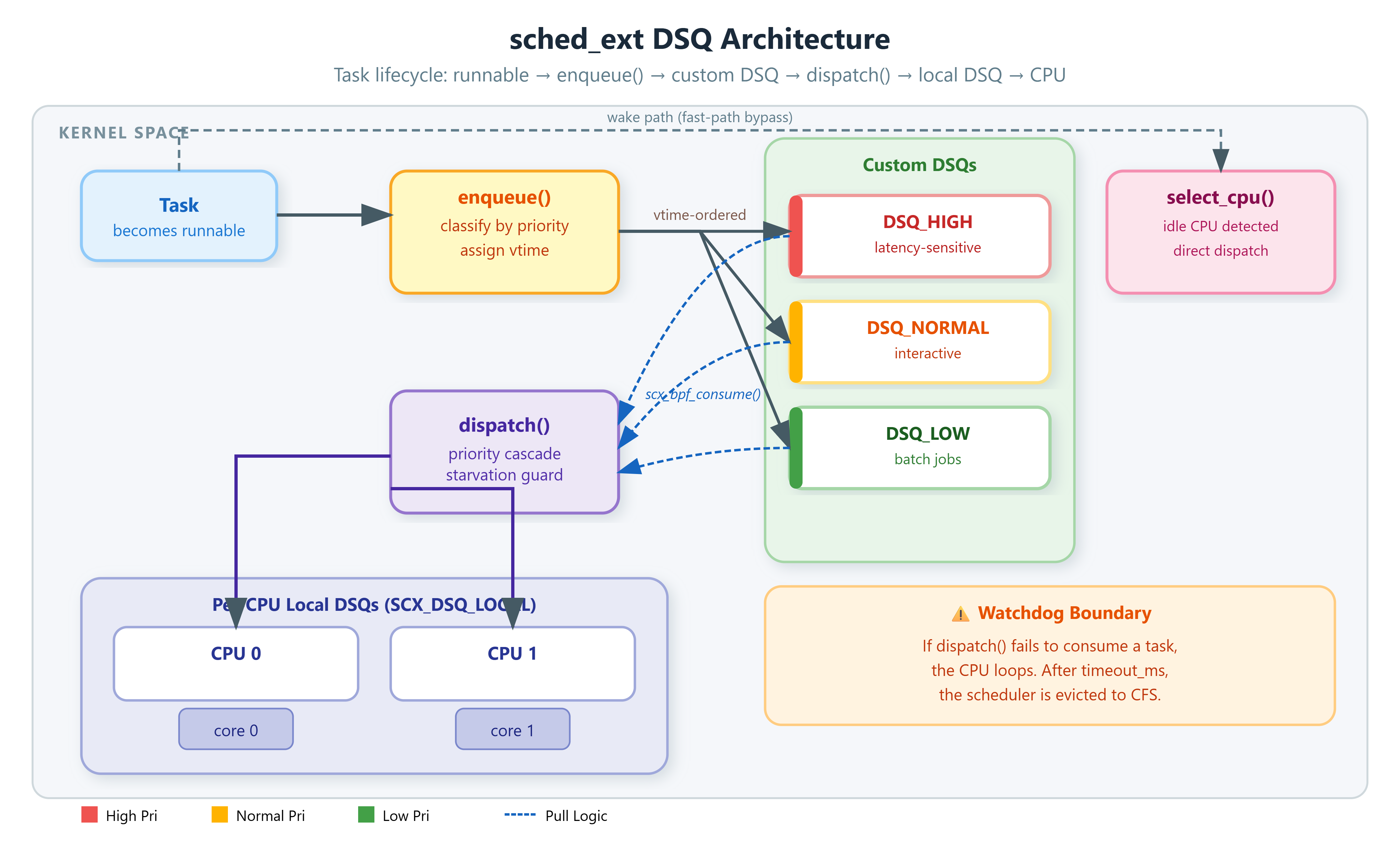
A DSQ is a kernel-managed, doubly-linked list of
task_structpointers with an associated spinlock and ordering semantics. The kernel maintains these: your BPF code never touches the list directly. When a task becomes runnable, yourenqueue()callback fires and you callscx_bpf_dispatch()orscx_bpf_dispatch_vtime()to place it in a DSQ. When a CPU goes idle, yourdispatch()callback fires and you callscx_bpf_consume()to move work from a DSQ into the CPU’s local DSQ — the per-CPU FIFO that the hardware actually runs from.Three built-in DSQ IDs exist:
SCX_DSQ_GLOBAL(a single system-wide FIFO any CPU can consume),SCX_DSQ_LOCAL(the calling CPU’s local DSQ, bypasses the consume step), andSCX_DSQ_LOCAL_ON(cpu)(another CPU’s local DSQ, used for load balancing inselect_cpu()). Any integer ≥ 1 is a valid custom DSQ ID after you create it.
Building the Multi-Priority DSQ Manager
Three custom DSQs map to three scheduling tiers: DSQ_HIGH (0) for latency-sensitive threads, DSQ_NORMAL (1) for interactive work, DSQ_LOW (2) for batch. Creation happens in init(), which runs in a sleepable BPF context — scx_bpf_create_dsq() acquires a mutex internally, so it cannot run from a non-sleepable program:
s32 BPF_STRUCT_OPS_SLEEPABLE(dsq_mgr_init)
{
s32 err;
if ((err = scx_bpf_create_dsq(DSQ_HIGH, -1))) return err;
if ((err = scx_bpf_create_dsq(DSQ_NORMAL, -1))) return err;
if ((err = scx_bpf_create_dsq(DSQ_LOW, -1))) return err;
return 0;
}
The -1 node argument means NUMA-agnostic allocation. For NUMA-aware schedulers, pass the memory node for the DSQ’s backing storage.
In enqueue(), tasks are classified via BPF_MAP_TYPE_TASK_STORAGE (per-task scratch space with zero overhead — no hash lookup, the pointer lives in task_struct itself) and dispatched with virtual time ordering for intra-tier fairness:
void BPF_STRUCT_OPS(dsq_mgr_enqueue, struct task_struct *p, u64 enq_flags)
{
struct task_ctx *tctx = bpf_task_storage_get(&task_ctx_map, p, 0,
BPF_LOCAL_STORAGE_GET_F_CREATE);
u32 tier = tctx ? tctx->priority : DSQ_NORMAL;
/* New tasks get current vtime minus grace window to avoid starvation */
if (!tctx->vtime) {
u64 now = READ_ONCE(vtime_now[tier]);
tctx->vtime = now > GRACE_WINDOW ? now - GRACE_WINDOW : 0;
}
scx_bpf_dispatch_vtime(p, tier, SCX_SLICE_DFL, tctx->vtime, enq_flags);
}
The dispatch() Callback Is Where It Gets Subtle
dispatch() fires when a CPU needs work. Strict priority cascading looks obvious:
void BPF_STRUCT_OPS(dsq_mgr_dispatch, s32 cpu, struct task_struct *prev)
{
if (scx_bpf_consume(DSQ_HIGH)) return;
if (scx_bpf_consume(DSQ_NORMAL)) return;
scx_bpf_consume(DSQ_LOW);
}
This is also a starvation machine. Under sustained HIGH + NORMAL load, DSQ_LOW tasks never execute. The fix introduces a weighted promotion check at the dispatch layer — track cumulative dispatch counts per tier and enforce a minimum service rate:
void BPF_STRUCT_OPS(dsq_mgr_dispatch, s32 cpu, struct task_struct *prev)
{
u32 key = cpu;
struct cpu_ctx *cctx = bpf_map_lookup_elem(&cpu_ctx_map, &key);
/* Guarantee LOW tier gets at least 1 dispatch per 16 HIGH dispatches */
if (cctx && cctx->low_dispatched * 16 < cctx->high_dispatched) {
if (scx_bpf_consume(DSQ_LOW)) { cctx->low_dispatched++; return; }
}
if (scx_bpf_consume(DSQ_HIGH)) { if (cctx) cctx->high_dispatched++; return; }
if (scx_bpf_consume(DSQ_NORMAL)) return;
scx_bpf_consume(DSQ_LOW);
}
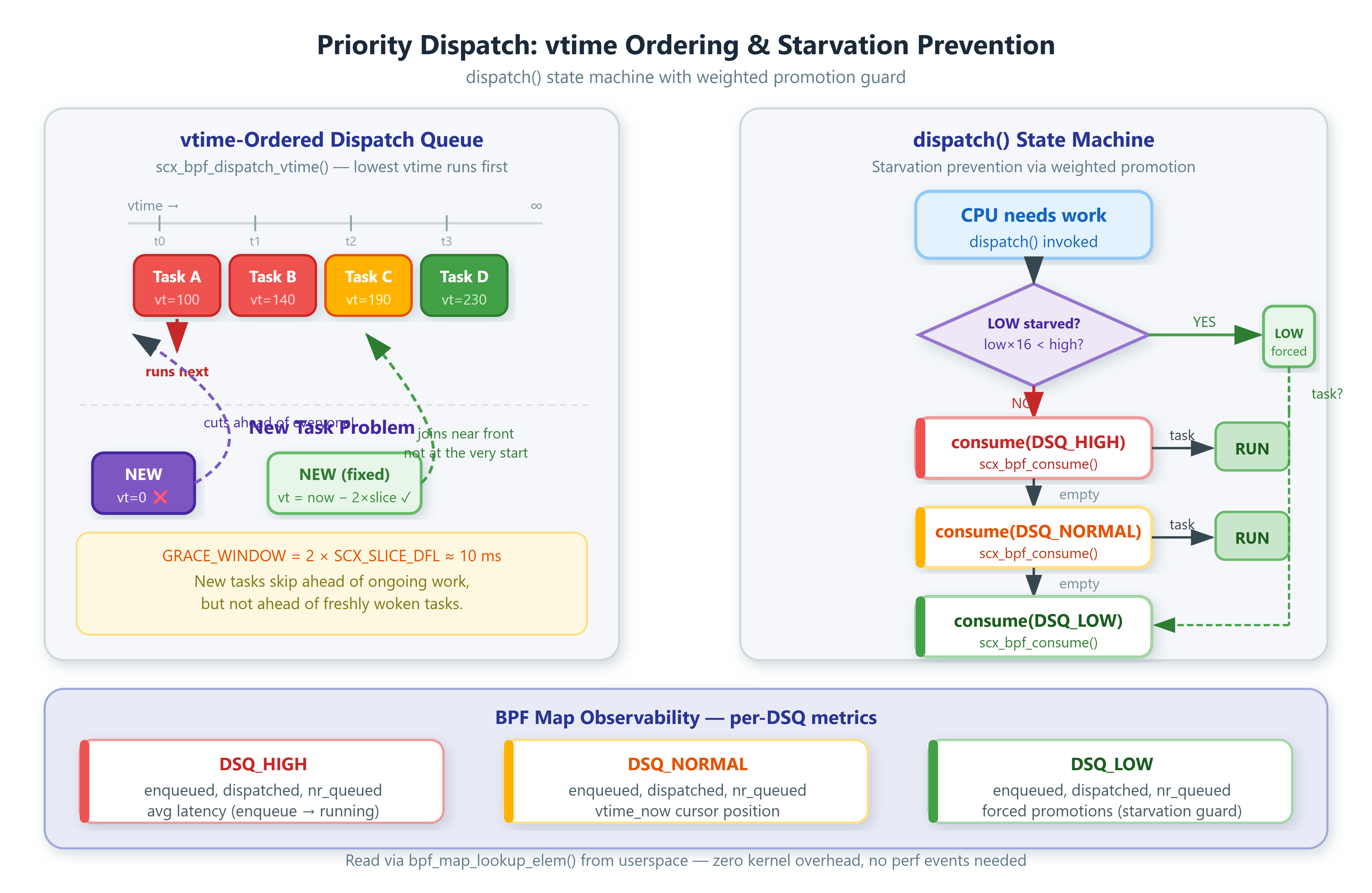
The New-Task Vtime Problem
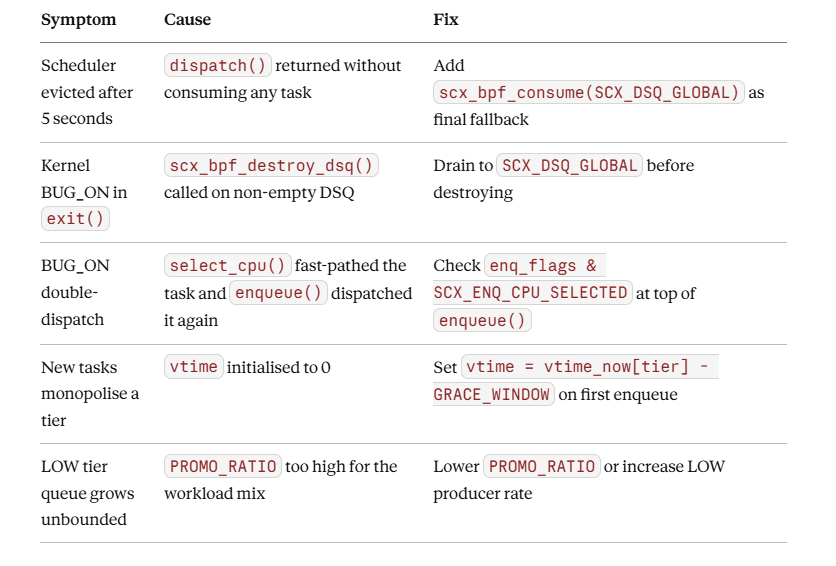
scx_bpf_dispatch_vtime() inserts tasks into the DSQ sorted by virtual time — lowest vtime runs first. A brand-new task initializing vtime = 0 will preempt every existing task in that tier. Fork 64 workers simultaneously and all 64 cut the line ahead of any running task. The grace window fix above (now - GRACE_WINDOW) lets new tasks skip ahead of recent work, but not ahead of a task that’s been waiting since the last scheduling epoch. GRACE_WINDOW = 2 × SCX_SLICE_DFL (about 10 ms) works in practice.
Production Failure Modes
The watchdog fires after timeout_ms (default 5000) if any runnable task goes unscheduled. The usual trigger: dispatch() returns without consuming anything and there’s no fallback path. Always terminate with scx_bpf_consume(SCX_DSQ_GLOBAL) as the last-resort fallback — it costs one lock acquisition and prevents the watchdog entirely.
The double-dispatch panic happens when select_cpu() fast-paths a task directly to SCX_DSQ_LOCAL (bypassing enqueue) and enqueue() also dispatches it. The fix is checking enq_flags & SCX_ENQ_CPU_SELECTED in enqueue() and returning early if the task is already dispatched.
Observability
The scheduler state lives at /sys/kernel/debug/sched_ext/root/ops. DSQ depths come from scx_bpf_dsq_nr_queued(dsq_id) polled via BPF maps in userspace. Per-task scheduling latency — the time from enqueue() to running() — requires storing bpf_ktime_get_ns() in task_ctx and computing the delta on the running() callback. Ring buffer the distribution and you have sub-millisecond latency histograms for each priority tier without any userspace tracing overhead.
The failure mode that catches everyone eventually: destroying a DSQ in exit() while tasks are still queued in it. scx_bpf_destroy_dsq() will BUG_ON if the DSQ is non-empty. Drain it first with scx_bpf_consume() in a loop, or dispatch remaining tasks to SCX_DSQ_GLOBAL before destroying.
Part II — Implementation
Why Three DSQs Instead of One
The natural instinct is to add a priority field to each task and sort a single queue. The DSQ model deliberately separates queues per priority class, with dispatch() deciding which queue to consume from. The reason this matters is vtime correctness. With a single queue, a LOW task at vtime=99 competes directly against a HIGH task at vtime=100 — the LOW task wins the comparison and runs first, which defeats priority entirely. Separate DSQs mean vtime comparisons are strictly intra-tier. A LOW task at vtime=99 never sees the HIGH task at vtime=100; they live in different queues and dispatch() controls which queue gets served.
Per-Task State Without Hash Overhead
The task_ctx struct — storing each task’s priority tier, virtual time, and enqueue timestamp — lives in a BPF_MAP_TYPE_TASK_STORAGE map. This is not a hash map. The kernel embeds a pointer directly in task_struct‘s bpf_storage field, so bpf_task_storage_get() is a pointer dereference, not a hash lookup. At the scale of thousands of runnable tasks hitting enqueue() every millisecond, this difference is measurable.
The BPF_LOCAL_STORAGE_GET_F_CREATE flag allocates the struct on first access. If allocation fails under memory pressure, the fallback dispatches directly to SCX_DSQ_GLOBAL — the task is never silently lost.
The select_cpu() Fast Path
select_cpu() runs before enqueue() when a sleeping task wakes up. When scx_bpf_select_cpu_dfl() finds an idle CPU, there is no reason to go through the enqueue-then-dispatch round-trip. Dispatching directly to SCX_DSQ_LOCAL cuts the path from wake event to execution by one full scheduler invocation and one lock acquisition.
The flag SCX_ENQ_CPU_SELECTED propagates into enqueue() to signal that this task is already handled. The enqueue() callback must check this flag and return immediately — if it dispatches the task again, the kernel’s accounting will BUG_ON a double-dispatch.
How Virtual Time Moves
The vtime_now[] array is a per-tier clock. Each entry advances by SCX_SLICE_DFL every time a task from that tier executes, inside the running() callback. A task entering a tier for the first time is given vtime = max(vtime_now[tier] - GRACE_WINDOW, 0).
This has two properties worth understanding. First, a task that was preempted and re-enqueued gets a vtime close to its previous value — the cursor has only moved by however many slices ran while it was off-CPU, so it re-enters near the front of the queue without cutting ahead of anyone waiting longer. Second, the grace window (two slices, around 10 ms) means new tasks get a small head start over tasks that have been accumulating vtime for a long time, but they cannot leap over a task that woke up two milliseconds ago. The window size is a trade-off: larger windows favour bursty workloads where new tasks need responsiveness; smaller windows enforce stricter fairness among long-running workers.
How the Starvation Guard Actually Works
The dispatch() callback tracks cumulative dispatch counts in a per-CPU map. The promotion condition reads: if LOW has received fewer than one dispatch for every sixteen HIGH dispatches, serve LOW next regardless of the normal cascade. This runs before HIGH gets checked, so it genuinely interrupts the priority ordering.
PROMO_RATIO = 16 gives LOW tier a floor of roughly 6% of CPU time under full HIGH saturation. The counters accumulate indefinitely and never reset — which is intentional. If HIGH stops generating work, the ratio naturally reverts as LOW dispatches catch up. There is no cleanup logic needed.
What the Simulation Demonstrates
dsq_sim.c replicates enqueue(), dispatch(), and running() in userspace using pthreads. Producer threads generate tasks at configurable rates per tier. A dispatcher thread runs the same priority cascade and starvation guard logic. Worker threads execute dispatched tasks. The ncurses monitor reads from the same atomic counters that the BPF maps would expose.
The simulation cannot replicate kernel scheduling pressure — it has no visibility into CPU idle states or hardware preemption. What it does show is the queue dynamics: run it in balanced mode and all three tiers drain steadily. Press d to switch to heavy-HIGH mode and watch the LOW queue depth climb until the starvation guard fires and drains it. That queue depth spike is exactly what you would see in production when bpf_dsq_nr_queued(DSQ_LOW) starts rising with no corresponding dispatched increments.
Building and Running
Github Link:
https://github.com/sysdr/howtech/tree/main/day90
Prerequisites
The userspace simulation compiles on any Linux system with gcc and ncurses. The BPF scheduler requires Linux 6.12+ with CONFIG_SCHED_CLASS_EXT=y, clang 16+, libbpf 1.4+, and bpftool.
Running the Simulation (any kernel)
To build and run natively without Docker:
cd src
gcc -Wall -Wextra -Werror -O2 -std=c11 -o dsq_sim dsq_sim.c -lpthread -lncurses
./dsq_sim
Inside the monitor, d toggles heavy-HIGH mode and q exits.
Building the BPF Scheduler (Linux 6.12+)
Generate vmlinux.h from the running kernel’s BTF data first — this header contains every kernel type definition the BPF program needs:
bpftool btf dump file /sys/kernel/btf/vmlinux format c > src/vmlinux.h
Compile the BPF object, generate the skeleton header, then compile the userspace loader:
clang -O2 -g -target bpf \
-I src/ -I /usr/include/bpf \
-c src/dsq_manager.bpf.c -o src/dsq_manager.bpf.o
bpftool gen skeleton src/dsq_manager.bpf.o > src/dsq_manager.skel.h
gcc -Wall -Wextra -O2 -o src/dsq_manager src/dsq_manager.c -lbpf
Load the scheduler with root privileges:
sudo src/dsq_manager
Verifying the Scheduler Loaded
Once dsq_manager is running, the kernel exposes the active scheduler name at a debugfs path:
cat /sys/kernel/debug/sched_ext/root/ops
That should print dsq_manager. To confirm the BPF programs are present in the kernel:
bpftool prog show name dsq_mgr_enqueue
bpftool prog show name dsq_mgr_dispatch
Each program’s instruction count and loaded timestamp will appear. If either is missing, check dmesg — a failed init() or BPF verifier rejection will produce a message there.
Setting Task Priority
To move a running process into the HIGH or LOW tier, pass its PID and the tier number to the loader while it is running. Tier 0 is HIGH, 1 is NORMAL, 2 is LOW:
sudo src/dsq_manager --priority $(pgrep my_latency_app) 0
The loader writes the desired tier into a BPF hash map. The next time init_task() runs for that process, it reads from that map and populates task_ctx.priority accordingly.
Watching It in Production
With the scheduler loaded, the three most useful things to observe in parallel are queue depth, dispatch latency, and the starvation counter.
Poll queue depths from userspace by reading the dsq_stats_map BPF map directly. The nr_queued field tells you how much work is sitting in each tier. If DSQ_LOW.nr_queued grows monotonically while dispatched stays flat, the starvation guard is not firing fast enough — lower PROMO_RATIO.
Scheduling latency comes from the latency_sum_ns / latency_count values the running() callback maintains. For the HIGH tier, latency over 500 microseconds on an unloaded system indicates contention in select_cpu() or excessive time spent in the BPF verifier’s instruction limit.
Use perf sched latency alongside the BPF stats for cross-validation. If perf shows high average wait times for SCHED_NORMAL tasks that your BPF maps show as HIGH priority, the classification logic in enqueue() is not reading task_ctx.priority correctly — check whether bpf_task_storage_get() is returning NULL for those tasks and the fallback path is dropping them into DSQ_NORMAL.
Cleanup
./cleanup.sh
This stops any running demo container, removes the Docker image, and deletes the compiled binary. The BPF scheduler unloads automatically when the dsq_manager process exits — the kernel detects the struct_ops link going away and falls back to CFS.
Quick Reference


Common Errors and What They Mean