CPU Selection in sched_ext: Dynamic Grouping and Wakeup Handling
When your latency-sensitive service shares a machine with batch workloads, the default CFS scheduler treats them democratically. Your 99th percentile latencies spike from 2ms to 50ms because a background MapReduce job just woke up on the same CPU, evicting your hot cache lines. Traditional scheduler tuning—nice values, cgroups, CPU affinity—helps, but you’re fighting the scheduler’s assumptions rather than encoding your workload’s actual requirements.
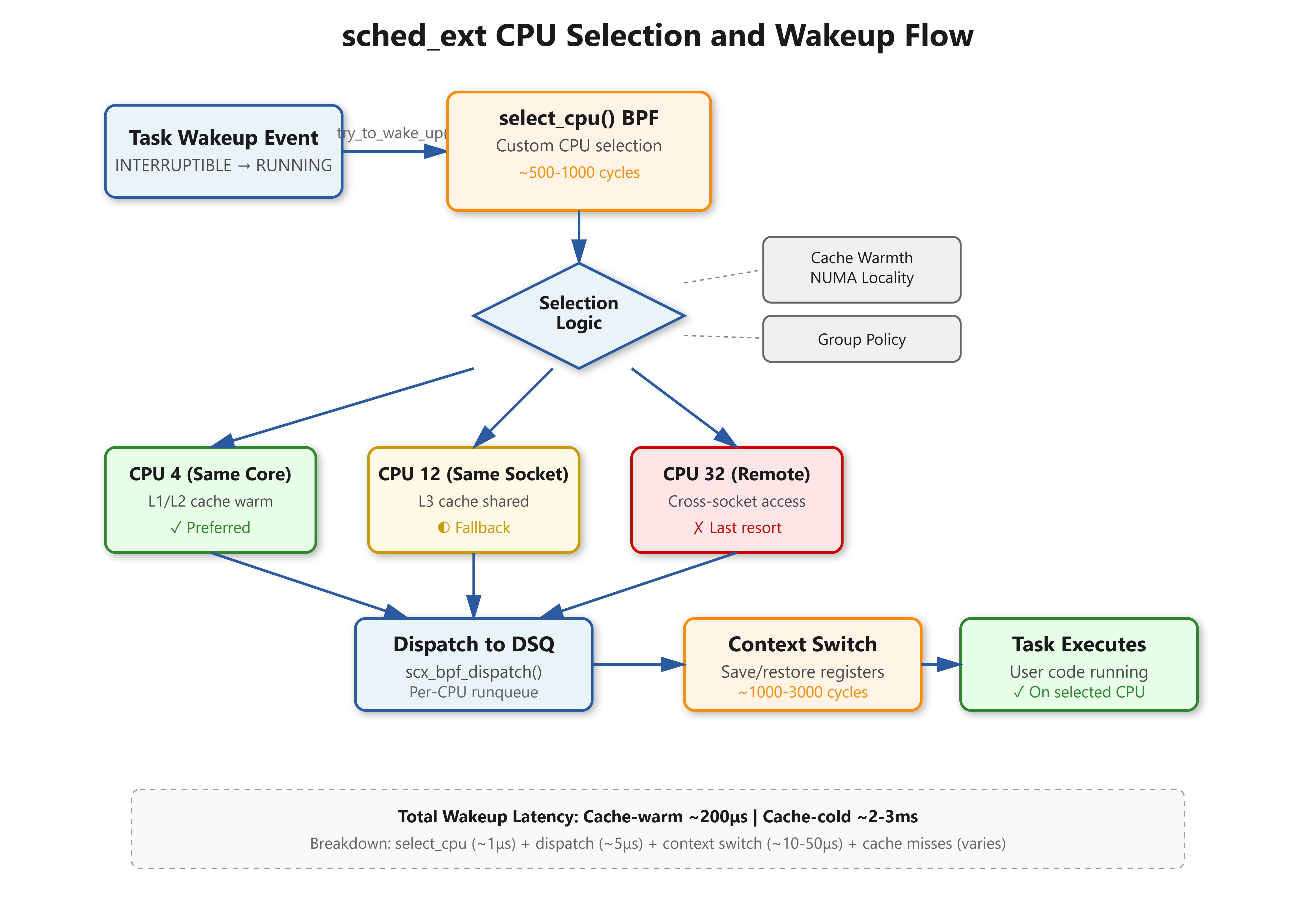
Linux 6.12’s sched_ext changes this entirely. You write a BPF program that implements select_cpu() and controls which CPU executes each task on wakeup. The difference shows up immediately: Netflix’s media encoder workload saw wakeup latency drop from 2ms to 200μs by grouping encoding tasks by complexity and keeping cache-warm data local.
The Wakeup Path Everyone Gets Wrong
When a task transitions from TASK_INTERRUPTIBLE to TASK_RUNNING, the kernel calls try_to_wake_up(). With CFS, you get whatever the load balancer thinks is fair. With sched_ext, your select_cpu() callback runs in BPF context and returns the target CPU. This happens millions of times per second, so your logic needs to be fast—under 1000 CPU cycles typically.
The mistake everyone makes: checking every CPU’s load. You’re in BPF, you can’t loop arbitrarily, and the verifier will reject unbounded iterations. Production schedulers use CPU masks. Mark preferred CPUs in a BPF array, iterate only those, pick the least loaded. Meta’s workload isolation scheduler keeps latency-sensitive tasks on CPUs 0-15, batch on 16-63, checked via
cpumask_test_cpu()against allowed masks.