
Building an Event-Driven Network Policy Engine with eBPF and Cilium
Part I — The Article
Run
iptables -Lon a node in a 500-node cluster and watch your terminal freeze. kube-proxy has written 40,000–60,000 rules acrossPREROUTING,FORWARD,OUTPUT, andPOSTROUTINGchains. Every inbound TCP SYN walks that list from the top. Conntrack tracks each flow with a global spinlock —nf_conntrack_lockserializes state insertion across all CPUs. Past 80,000 connections per second, you’re not hitting application limits; you’re hitting the kernel’s rule traversal and lock contention. The symptom is risingsysCPU, conntrack drops in/proc/net/stat/nf_conntrack, and kube-proxy restarts that take 45–90 seconds to reload rules while policy is inconsistent.
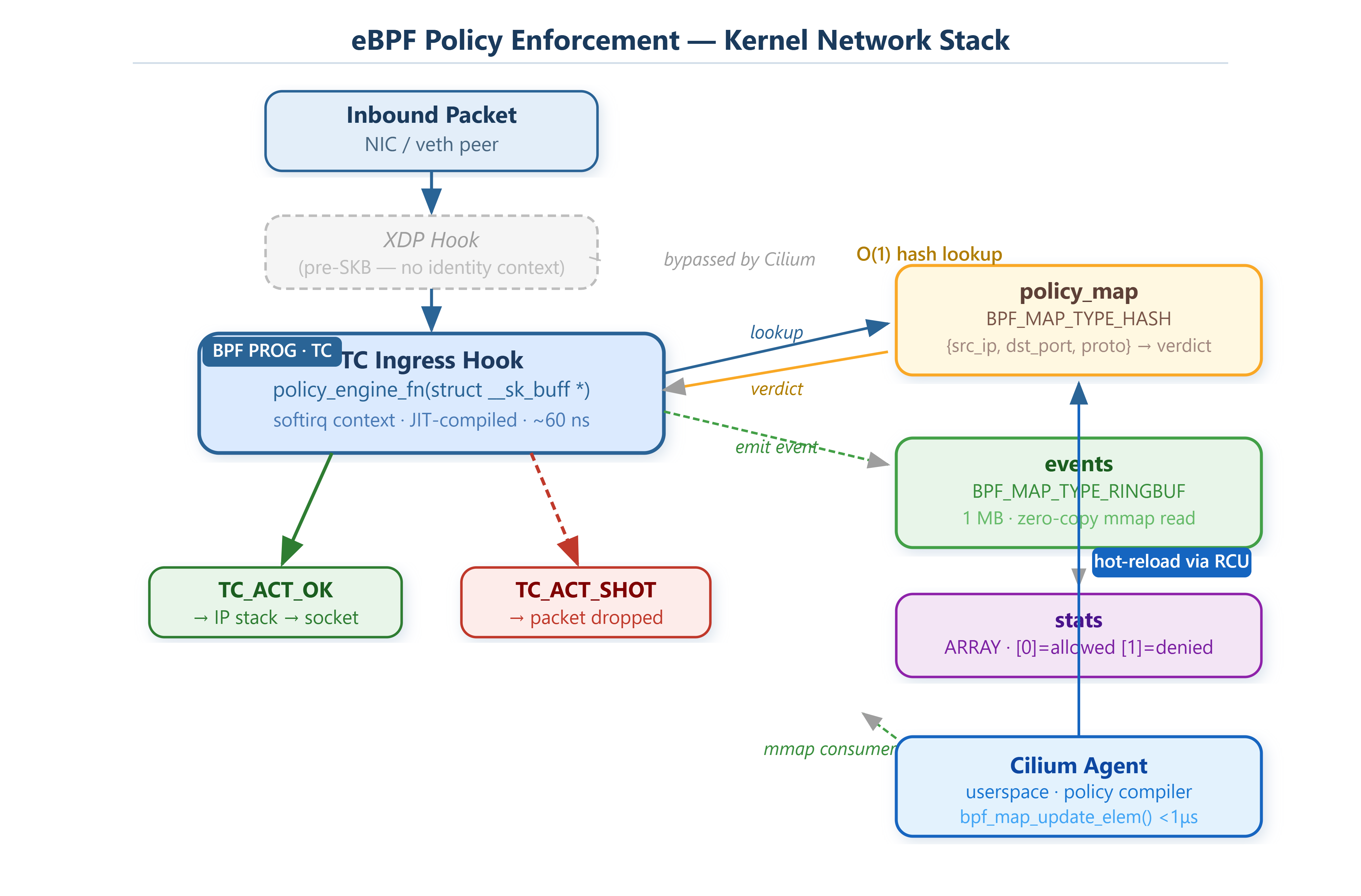
Cilium replaces this path entirely. Instead of iptables chains, it loads BPF programs at the TC (Traffic Control) ingress hook — positioned in the kernel right after netif_receive_skb() processes the incoming socket buffer, before any IP stack involvement. At this hook, the kernel has a fully formed sk_buff: VLAN tags, checksum validation status, ingress interface metadata, and crucially, the cgroup context needed to identify which pod sourced the packet. XDP runs earlier — at the NIC driver, before SKB allocation — but XDP can’t access socket-level identity. TC is where policy enforcement lives.
The BPF program is JIT-compiled to native x86-64 via do_jit() in arch/x86/net/bpf_jit_comp.c. It runs in softirq context with no process context switch, no scheduler involvement. Measured overhead for a two-map lookup plus ring buffer write: 50–80ns per packet. Comparable iptables traversal at similar rule counts costs 2–5μs.
Policy as BPF Maps
Network policies don’t compile to bytecode — they compile to map entries. Cilium assigns every workload a 32-bit security identity by hashing its label set (namespace, app, version, etc.). This identity is immutable for the workload’s lifetime and stored in the ipcache BPF map: IP → identity. A second map — policy_map — stores {src_identity, dst_port, protocol} → verdict.
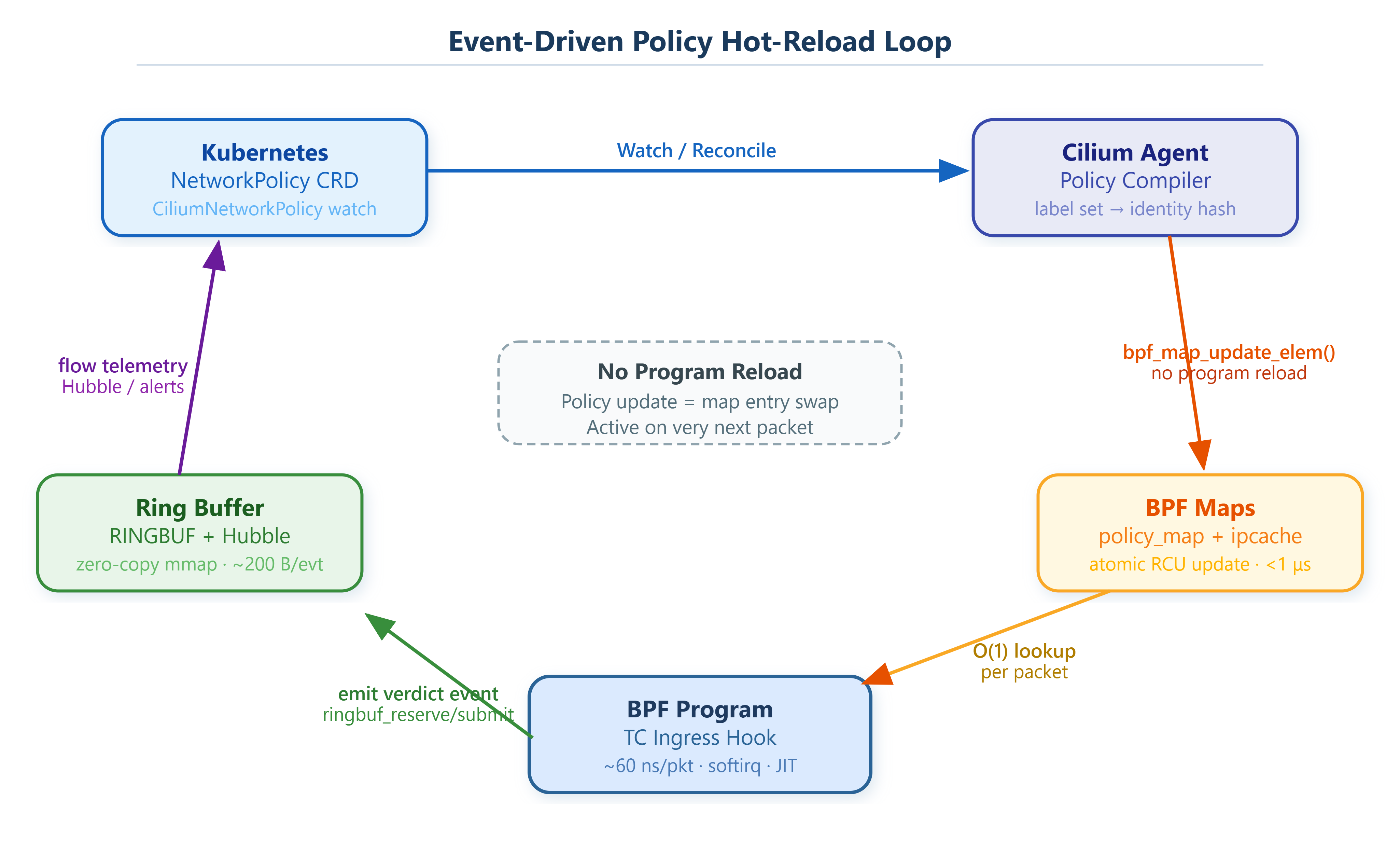
When a packet hits the TC hook, the BPF program executes two hash map lookups — first for exact source match, then a wildcard fallback — and reaches a verdict in roughly 15–20 BPF instructions. Map updates don’t require reloading any program. bpf_map_update_elem() takes an RCU write lock internally, making the new entry atomically visible to all CPUs in under a microsecond. You can push a policy change from the Cilium agent and have it enforced on the next packet, with no restart, no lock window, no inconsistency period.
For CIDR-based rules (10.0.0.0/8), use BPF_MAP_TYPE_LPM_TRIE rather than a hash map. The LPM trie does longest-prefix matching in O(prefix_bits) comparisons, not O(entries). A hash map would require one entry per host IP to approximate CIDR matching — impractical at scale.
Event Streaming via Ring Buffer
Every verdict emits an event. Before kernel 5.8, Cilium used BPF_MAP_TYPE_PERF_EVENT_ARRAY — one ring per CPU, fixed record sizes, memory wasted on idle CPUs, multi-CPU reads requiring per-CPU iteration. The BPF_MAP_TYPE_RINGBUF introduced in 5.8 uses a single shared ring with a reservation protocol that avoids locks for concurrent writes from multiple CPUs. Records are variable-length. The consumer reads via mmap() — no read() syscall, no kernel-to-userspace copy.
The two-phase write prevents torn reads: bpf_ringbuf_reserve() atomically claims space and returns a pointer directly into the ring memory. bpf_ringbuf_submit() flips the record’s visibility bit. The userspace consumer (libbpf‘s ring_buffer__poll()) calls your callback with a pointer to ring memory — zero copy end to end.
Back-pressure is intentional: if the consumer falls behind, bpf_ringbuf_reserve() returns NULL and events are dropped rather than blocking the BPF program. Track this with bpftool map show id <id> and watch the value_size against max_entries. In production, size the ring buffer at 4–16MB per high-traffic interface.
Observability Without Overhead
cilium monitor --type drop reads directly from the ring buffers Cilium’s BPF programs already write. No promiscuous mode, no packet copy, no additional hook. Each drop event carries source endpoint identity, destination identity, ingress/egress direction, dropped port, and the rule that matched. At 200 bytes per event, even 500k drops/sec costs 100MB/s of ring buffer throughput — manageable, and the BPF program itself isn’t slowed.
TC Attachment
TC attachment requires a clsact qdisc on the interface first:
tc qdisc add dev eth0 clsact
tc filter add dev eth0 ingress bpf pinned /sys/fs/bpf/policy_engine direct-action
The direct-action flag is load-bearing. Without it, TC interprets the BPF return value (TC_ACT_OK, TC_ACT_SHOT) as a traffic class identifier and reroutes to an action chain that doesn’t exist — silently passing all packets. Every production deployment that’s switched from XDP to TC and lost policy enforcement for 20 minutes has hit this.
Pin the loaded program to /sys/fs/bpf/ with bpf_program__pin() before calling tc filter add. The pinned path persists across process exits; the TC filter survives until explicitly removed or the interface goes down.
Part II — Implementation
Github Link:
https://github.com/sysdr/howtech/tree/main/day85/ebpf-policy-engine
What You’re Building
Two source files, a Makefile, and an isolated network namespace give you a fully working policy engine you can interrogate in real time.
The BPF program (policy_engine.bpf.c) runs in the kernel as a TC classifier. It consults a hash map on every inbound packet and writes a structured event — source IP, destination port, protocol, verdict, nanosecond timestamp — to a ring buffer. The userspace program (policy_engine.c) loads the BPF object, pins it, attaches it to a veth interface, seeds the policy map with two rules, then opens an ncurses dashboard that consumes the ring buffer live and lets you swap policy entries interactively.
Everything compiles under -Wall -Wextra -Werror -O2. No mocked syscalls, no simulated output.
System Requirements
Ubuntu 22.04 or newer. Linux kernel 5.10 minimum — the ring buffer landed in 5.8, but the libbpf 0.5 API shipped in Ubuntu 22.04 targets 5.10 as its stable baseline. Run uname -r to check. All other dependencies (clang, libbpf-dev, libncursesw5-dev, iproute2, bpftool) are installed automatically at the start of demo.sh. Root access is required — BPF program loading and tc attachment both need CAP_NET_ADMIN and CAP_BPF.
How the BPF Program Is Structured
The three BPF maps declared at the top of policy_engine.bpf.c tell the whole story. policy_map is a BPF_MAP_TYPE_HASH keyed on {src_ip, dst_port, protocol} — zero in src_ip means wildcard. events is the BPF_MAP_TYPE_RINGBUF at 1MB. stats is a two-element BPF_MAP_TYPE_ARRAY: index 0 counts allowed packets, index 1 counts denied ones.
The program section is declared SEC("classifier") rather than the newer SEC("tc"). On Ubuntu 22.04’s libbpf 0.5, section-name autodetection for TC programs is incomplete, so SEC("classifier") is the portable choice. The userspace loader reinforces this with an explicit bpf_program__set_type(prog, BPF_PROG_TYPE_SCHED_CLS) call before bpf_object__load().
Inside policy_engine_fn(), the packet parsing is deliberately conservative. Every bounds check uses the pattern if ((void *)(header + 1) > data_end) return TC_ACT_OK. The BPF verifier requires these — it tracks every pointer offset from skb->data and rejects programs that could read past data_end. Non-IP frames (non-0x0800 ethertype) pass through immediately; only TCP and UDP populate the port fields that policy lookup uses.
check_policy() does two map lookups: exact source IP first, wildcard (src_ip = 0) second. The __sync_fetch_and_add(&e->hits, 1) on a matched entry is a BPF built-in atomic — it increments the per-rule hit counter without needing a dedicated lock map. The default when neither lookup hits is VERDICT_ALLOW.
The ring buffer write uses the reserve/submit pattern:
struct pkt_event *ev = bpf_ringbuf_reserve(&events, sizeof(*ev), 0);
if (ev) {
ev->src_ip = ip->saddr;
ev->ts_ns = bpf_ktime_get_ns();
/* ... other fields ... */
bpf_ringbuf_submit(ev, 0);
}
The NULL guard on bpf_ringbuf_reserve() is not optional. If the consumer is too slow and the ring is full, reserve returns NULL. The BPF verifier will reject any program that dereferences the pointer without checking it first.
How the Userspace Loader Works
policy_engine.c loads the compiled BPF object with bpf_object__open(BPF_OBJ), sets the program type explicitly, calls bpf_object__load(), then pins the program to /sys/fs/bpf/policy_engine_prog. The pin creates a filesystem reference that outlives the process — tc filter add ... bpf pinned <path> direct-action looks up this path when attaching.
TC attachment happens through a system() call rather than libbpf’s bpf_tc_hook_create(). The hook API landed in libbpf 0.6; Ubuntu 22.04’s packaged version is 0.5. The shell commands are equivalent:
tc qdisc add dev veth-policy clsact
tc filter del dev veth-policy ingress # idempotent
tc filter add dev veth-policy ingress bpf pinned /sys/fs/bpf/policy_engine_prog direct-action
After attach, two policy entries are written with bpf_map_update_elem(). The first denies TCP port 8080 from any source (src_ip = 0). The second allows ICMP from the peer IP (10.99.0.2). The ring buffer consumer is set up with ring_buffer__new(efd, handle_event, NULL, NULL). On each ring_buffer__poll(rb, 100) call, libbpf reads the ring via its mmap()-ed region, calls handle_event() for each submitted record, and returns.
The ncurses dashboard runs in the main thread. ring_buffer__poll() and getch() both have short timeouts so neither blocks the other. Keypress A calls bpf_map_update_elem() with VERDICT_ALLOW for the TCP/8080 key — the change takes effect on the very next packet without touching the loaded BPF program. Keypress D restores the deny entry. Keypress C iterates all keys via bpf_map_get_next_key() and deletes them, which restores the default-allow behavior.
Running the Demo
sudo ./demo.sh
The script compiles both sources, creates a veth pair with veth-policy on the host side and veth-peer inside a fresh policy-test network namespace (10.99.0.1/24 and 10.99.0.2/24 respectively), mounts the BPF filesystem if needed, and starts three background traffic generators inside the namespace: continuous ICMP ping, periodic TCP connections to port 80, and periodic TCP connections to port 8080.
Once the monitor opens, the ICMP and TCP/80 flows show [ALLOW] in green. TCP/8080 connections show [ DENY] in red — the BPF program is dropping those packets before the IP stack processes them. The peer-side nc connecting to 8080 gets no RST, no ICMP unreachable — just silence, because TC_ACT_SHOT discards the packet entirely.
Press A. The policy map entry for TCP/8080 flips to VERDICT_ALLOW in under a microsecond. The next TCP/8080 attempt shows [ALLOW]. There is no BPF program reload, no tc filter del and re-add, no restart of anything. Press D to restore the deny rule.
The stats map accumulates throughout. After quitting, the final allowed and denied counts are printed to the terminal. To verify directly:
bpftool map show # find the policy_map and stats map IDs
bpftool map dump id <stats_id>
What to Watch For
The direct-action flag is the most common TC/BPF misconfiguration. With it absent, TC_ACT_SHOT becomes a traffic class ID pointing at a nonexistent action chain — all packets pass. The symptoms look identical to a BPF verifier rejection or a wrong attach point: traffic flows when it shouldn’t. Add direct-action and the behavior flips instantly.
The SEC("classifier") versus SEC("tc") distinction matters on older libbpf. If the program loads but verdicts have no effect, check the actual program type with bpftool prog show — if it shows socket_filter instead of sched_cls, the section name was not recognized and the load silently used a wrong type.
The ring buffer’s 1MB ceiling is intentional for a demo. Under real load — thousands of packets per second — you’ll see the userspace consumer fall behind. The bpftool map show output on the events map reports bytes consumed and bytes available. When bytes available is consistently near max_entries, double the max_entries value in the BPF source and recompile. You do not need to modify the loader.
Cleanup
sudo ./cleanup.sh
Removes the TC filter, the clsact qdisc, the BPF pin, the veth pair, the network namespace, and the build directory. Running demo.sh again starts from a clean slate.